日志收集
日志现状(小时级别)
每个服务大约都是百兆级别
日志方案(主要在采集与聚合的差别)
node node{
storage Agent
}
storage MQ
storage Collector
storage Storage
storage Visualization
Agent -> MQ: buffering
MQ -> Collector: filtering and aggregate
Collector -> Storage: index and store
Storage-> Visualization: analysis and visualization
- ELK(logstash) filebeats :采集日志,简单进行格式转换,相对于logstash速度更快,资源消耗更小 logstash: 一个java进程,资源消耗较大,具有丰富的过滤功能(特别吃内存 ) es: 存储 kibana:可视化与分析 MQ:消息中间件
node node
storage filebeats
storage logstash
storage MQ
storage es
storage kibana
node-> filebeats: collection
filebeats->MQ: buffering
MQ-> logstash: aggregate and filtering
logstash -> es: index and store
es -> kibana: analysis and visualization
-
EFK(Fluent) F:Fluentd(Apache 2.0) 相对于ELK 取代重量级别的,c语言开发,官方文档描述30~40M的内存能够1300日志事件/秒/核 F:Fluent bit 更加轻量级 资源消耗小 过滤处理能力较弱 适合于小型日志收集
-
logstail(阿里云) 占用机器cpu、内存资源最少,结合阿里云日志服务的E2E体验良好,但目前对特定日志类型解析的支持较弱
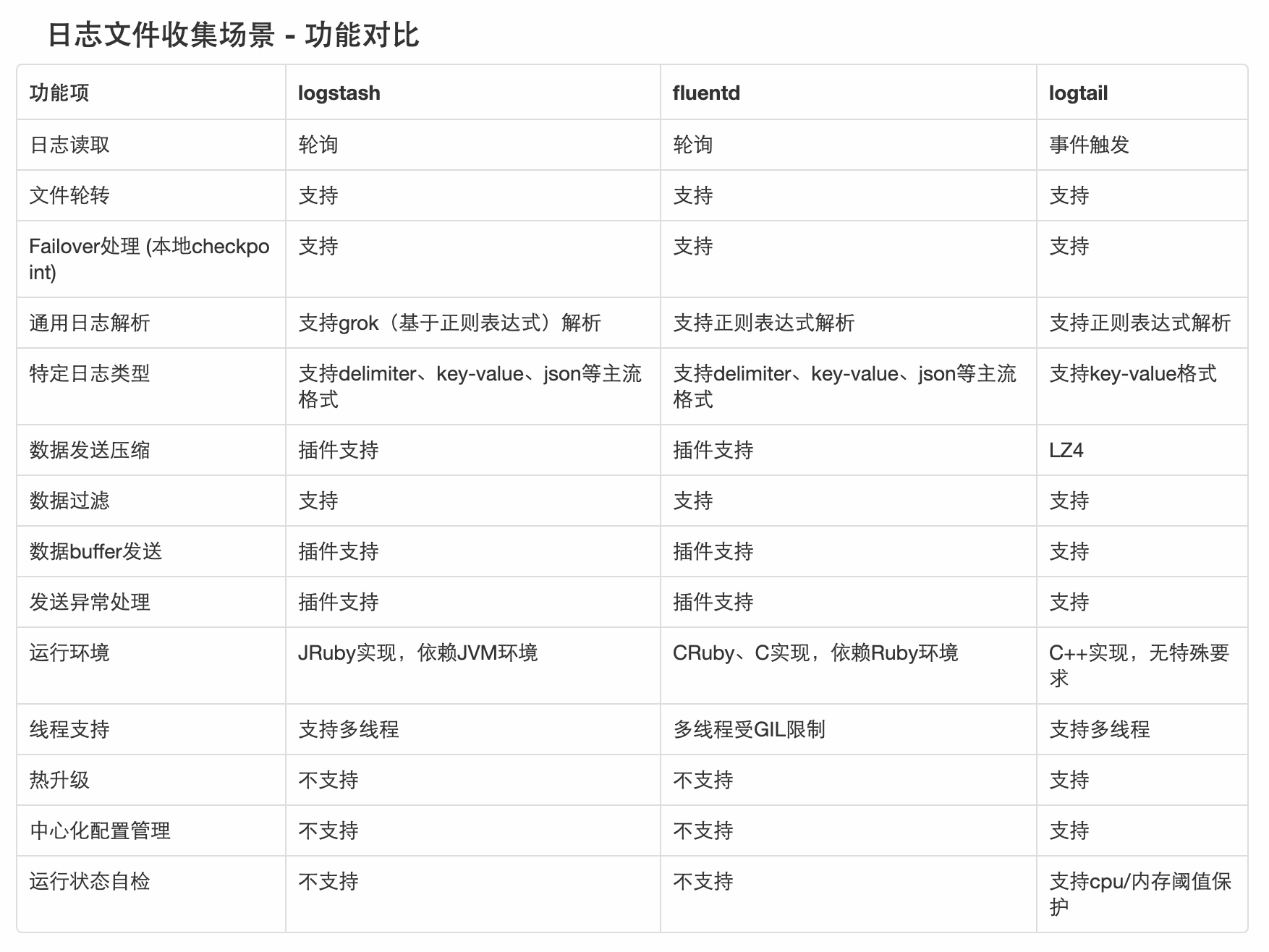
日志收集场景对比
功能对比
性能对比
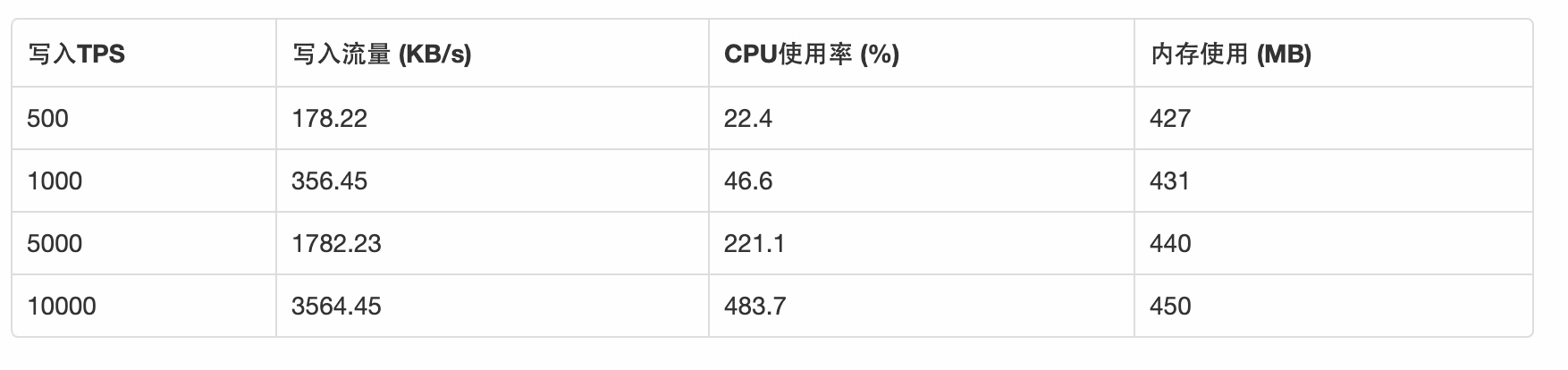
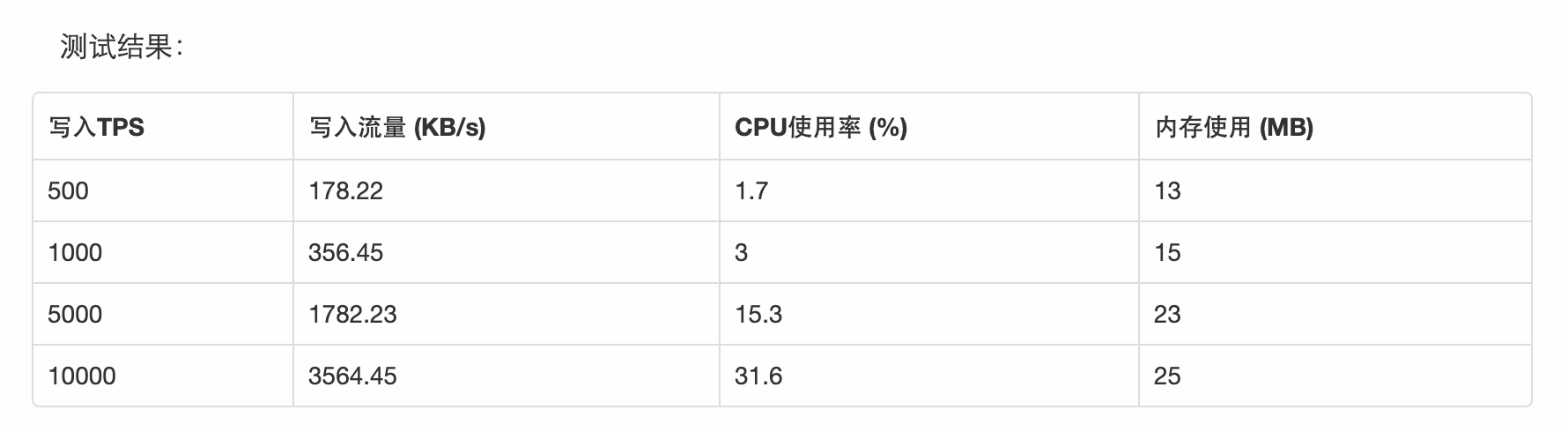
前提: 以Nginx的access log为样例,如下一条日志365字节,结构化成14个字段:
-
logstash
-
fluentd
-
logtail